Why you should be using your data warehouse to sync your SaaS tools
The most robust and simple way to sync between production systems is to use your warehouse as the single source of truth


Syncing business data between 3rd party tools has become fairly common. The marketing team wants to see customer support tickets, the customer support team should be able see previous orders, the sales team needs to see all previous interactions with an account, etc.
Consequently in the past few years nearly every SaaS tool has started offering their own set of integrations to other services.
At Narrator we use dozens of third-party SaaS products and have some kind of integration with nearly all of them. We send lists of customers to email from our internal database to Sendgrid, sync calendar data to our CRM, send leads from our website to Salesforce, etc.
Given dozens of systems each supporting hundreds of integrations, most companies do a point to point integration like this:
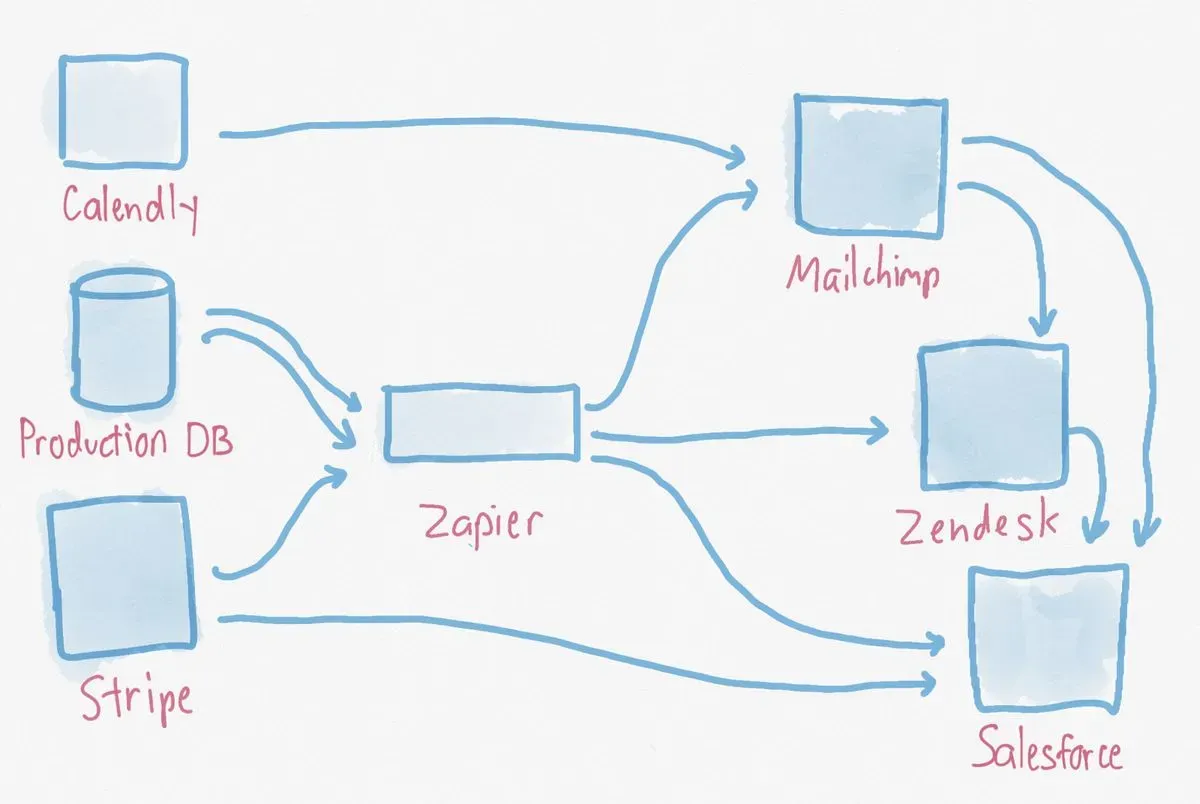
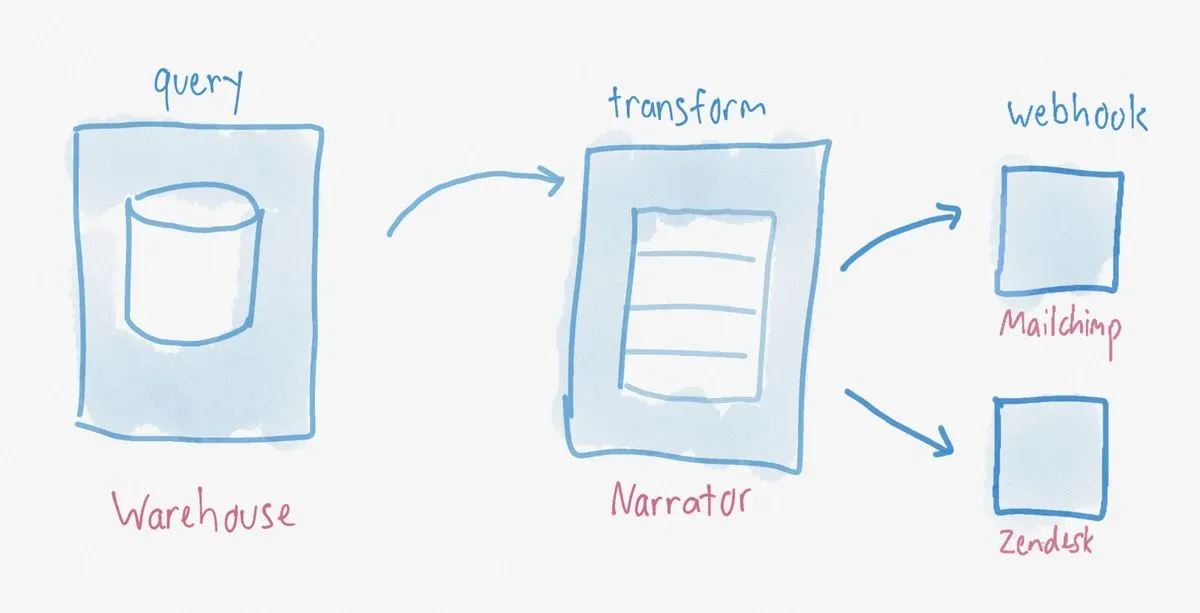
At Narrator we’ve been using a hub and spoke model with our data warehouse as the single source.
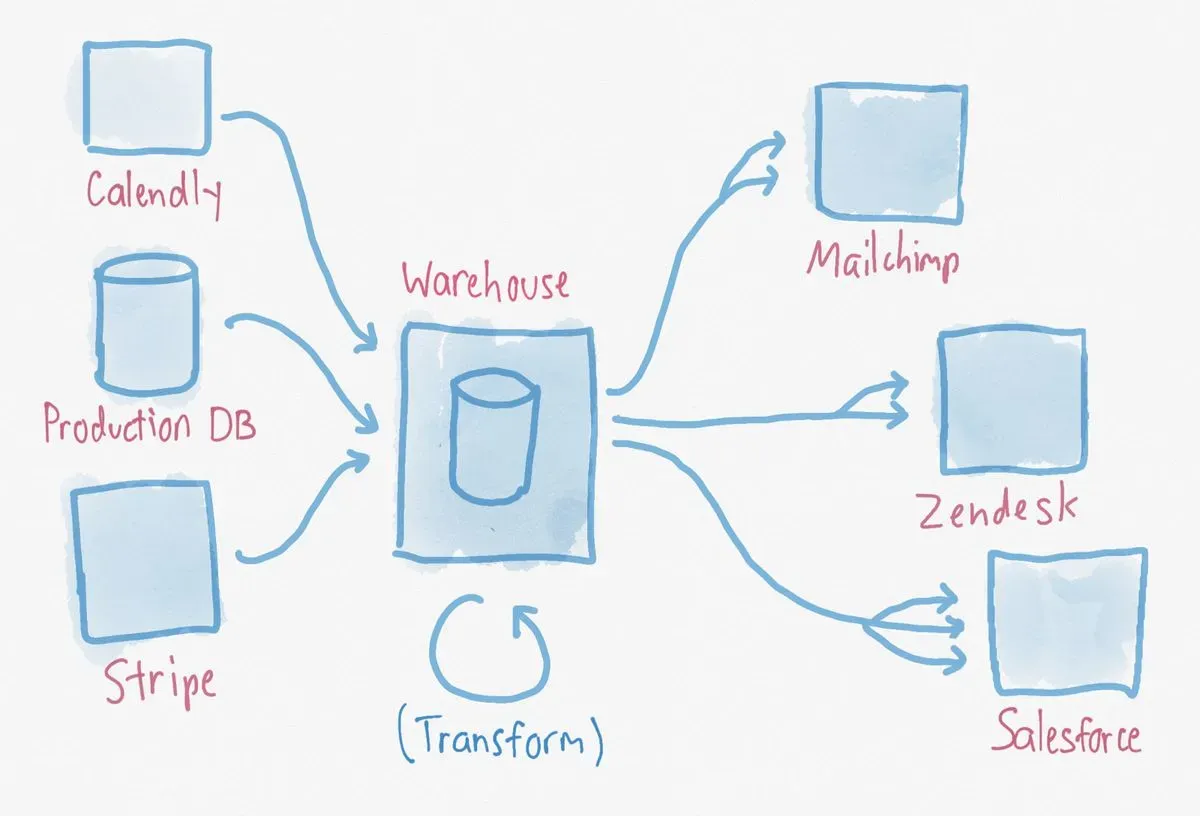
Our warehouse already has all our source data. Using it as the single source of truth for integration means that everything matches and is self consistent.
Though this is a much simpler diagram, it’s less common in practice. Tools like Narrator that facilitate syncing from the warehouse are less-widely known and relatively new.
I’ll spend the rest of this post showing why a warehouse-first approach is far better in the long run.
Quick note on real-time data synchronization
All the strategies below are for systems that can handle a sync delay of a few minutes to a few hours
This post is not about syncing real-time production data within your own systems!
In other words, a warehouse isn't a great solution for synchronizing internal data between your own (micro)services. Those have very different constraints (like an API call to System B should return up to date info, even if part of it is owned by System A).
What’s the problem?
Let’s start by assuming point to point integrations are consistent and up to date — I’ll save data quality and consistency concerns for the end. There are a lot of reasons why these types of integrations can be problematic, but I’ll focus on one.
Point-to-point integrations as a strategy is super inflexible. Sometimes you’re lucky enough to use a fully-supported integration that matches your use case perfectly. But many times you’re not.
For example, let’s say you’re working in Customer Support using Zendesk. You’d like to see which email campaigns that customers have received. If your marketing team uses Mailchimp you’re in luck. Zendesk supports it.
What about going the other way? What if marketing wants to send an email to customers who have recently submitted a ticket? Unfortunately that’s not supported. Or at least I didn’t find it.
Ok, so the marketing team will have to find a workaround.
So what about all customer orders? Seems reasonable that each time an agent is chatting with a customer they can pull up order information. If you’re using Stripe you’re out of luck. There’s no such integration. There’s one for Shopify, but it’s no longer supported by Mailchimp. They recommend another third-party service that literally does only that one integration.
The problem is that all the different ways you’re going to want to integrate data far exceeds the prebuilt integrations out there. And of course you don’t know ahead of time what’s possible. You’ll need to look to see if it’s natively supported; if not is it supported by a service you already use, like Zapier; and if not, is there some simple other workaround? Multiply this times the hundreds of integrations you’ll do.
In practice things quickly get even more complicated. Our customer service team doesn’t just want to see a customer’s orders and support tickets. They want to see a list of at-risk customers. Oh, and so does the marketing team.
Let’s say (for the sake of example) that we define an at-risk customer as someone who hasn’t ordered in the last 30 days but has submitted a support ticket in that time. You can’t sync that list to Zendesk or Mailchimp. It doesn’t exist. You’ve got to define it somewhere.
These types of computed values pop all over the place. The sales team wants to score leads to identify which ones to focus on (total marketing site pages viewed before the lead was submitted). The marketing team wants to send a coupon to customers who put something in their cart but didn’t check out last week.
These start to sound like data questions don’t they? And since these types of questions use data across systems, it’s likely your data warehouse is the only place that can answer them.
So far we’ve identified two problems
- the integration you’ll need between two systems may or may not exist
- some integrations require combining data from multiple systems
A warehouse is clearly an excellent solution to problem 2: it has all the relevant data, we know how to query it, and it’s (or at least it should be) straightforward to combine data from various systems.
So what about problem 1? A warehouse cuts that problem down drastically. Once you’re able to get data from the warehouse into one destination (using webhooks or an intermediary like Zapier) then you can repeat the same approach for most other destinations.
So what does a proper integration with a warehouse look like?
Avoiding integration
Before we dive into how to integrate using a warehouse, I want to point out one additional advantage: often you don’t have to integrate at all.
Ask yourself: will the target system use the data you’re sending in a fundamental way? Or is it just additional information you want to see at the same time?
For example, building a Mailchimp email list is fundamental — it wouldn’t know what to email otherwise.
Viewing additional information about a customer in Zendesk (recent orders, marketing emails received) isn’t really fundamental to Zendesk. In fact, there’s no obvious place to show this info (you’ll have to define a custom field).
Rule of thumb: it’s fundamental if it’s a predefined concept that exists by default. Tickets for Zendesk, leads for Salesforce, orders for Stripe, email lists for Mailchimp, etc.
If the data you’re sending isn’t one of the service’s core concepts then you can probably avoid sending it in the first place.
And nothing is easier than an integration that doesn’t have to happen.
Broadly there are two ways to avoid syncing: embedding and linking.
Option 1: Embed
If you have control over the app used by the end user, then you can embed the data they need right there.
Let’s go back to the Zendesk example. We’d love to see which customers are at risk, and for each one see their recent orders and marketing emails.
If you have a tool to build charts / dashboards you can show them directly in an app by embedding them (typically in an iframe).
Many BI tools support this kind of embedding automatically, so this can be a a fairly straightforward approach.
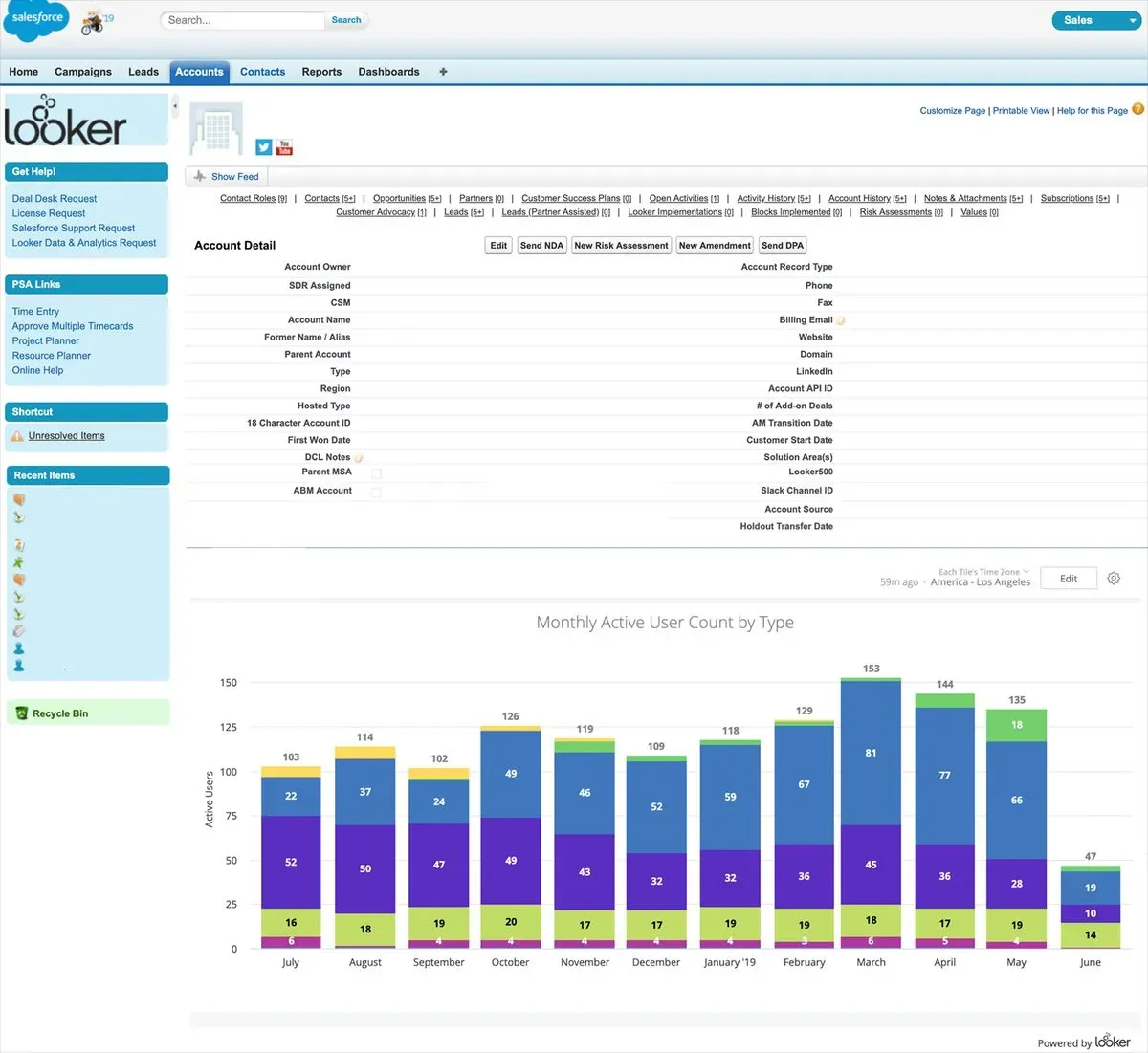
Not all third-party tools allow this, but Zendesk does, as does Salesforce.
We did this exact approach at a previous company — we used our warehouse to show additional metrics to our customer support team.
Pros: Data always up to date, can come from anything in the data warehouse, and is shown right where the user is working
Cons: sometimes requires some engineering work; only applies to apps where embedding is an option.
Option 2: Link to the data
If you can’t embed the data directly into an app’s UI the next best thing is to show a link to a data tool with the right information.
This is fairly simple to implement. Most BI tools allow linking directly to dashboards, with configurable parameters like user email.
Getting the link into the destination system isn’t always straightforward. If the target system doesn’t have a way to generate a url then you might have to send one in as a custom field (Zapier can listen to a user created in Zendesk and update a custom field on that user with the url ). And sure, at that point it might be worth just sending the actual data — but a link will point to much more data, from many systems, that is always up to date. And the link itself presumably hardly (if ever) changes, so it won’t suffer from sync issues.
Over the last year, more of our customers have started adding links directly to Narrator’s customer journey in Salesforce. This gives the sales person a clear timeline of the customer’s interaction with all systems, nicely cleaned and organized.
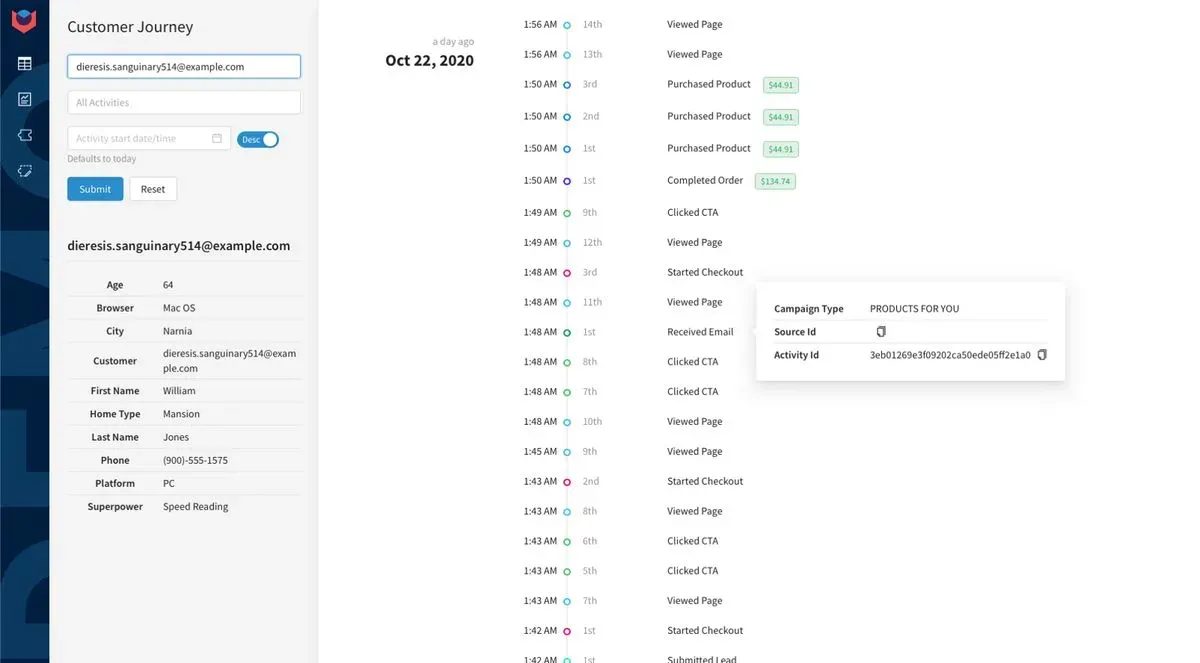
Pros: Data is always correct and up to date
Cons: User has to open another interface; getting the link into the destination system could require a little work
Warehouse Integration
So what about when you really do have to send data to a destination?
Let’s go back to building an email list in Mailchimp.
You need to do two things
- Collect and transform data into the proper format for the destination system
- Send the transformed data to the destination system
Transform
A warehouse is ideal for transforming data — it will have access to the raw data from all source systems and can be easily queried in SQL.
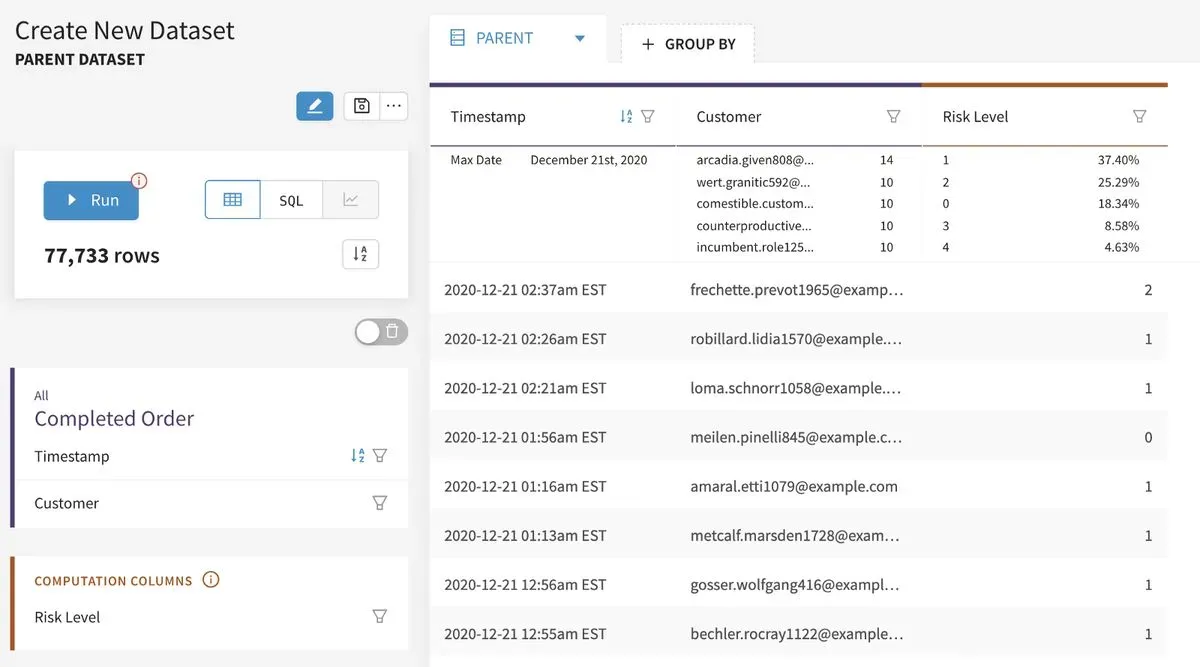
To set up on ongoing integration you’ll need to build a SQL transformation that runs on a regular basis. Tools like Narrator and dbt are excellent for this. Both can create new tables (materialized views) in the warehouse with transformed data and keep them up to date.
Here’s Narrator’s Dataset tool creating a list of customers along with their risk level
Send
Sending transformed data to a destination system is really straightforward.
One of the primary reasons companies build point to point integrations in the first place is because transformation is difficult. The Shopify to Mailchimp integration has to understand Shopify’s data format and transform it for Mailchimp. If you’ve already transformed it yourself you only have to send it.
If you already have data in the right format most destinations will accept it through webhooks. And if not, tools like Zapier will listen to a webhook and send the data to the destination
Luckily for our example Mailchimp supports using webhooks to manage email lists.
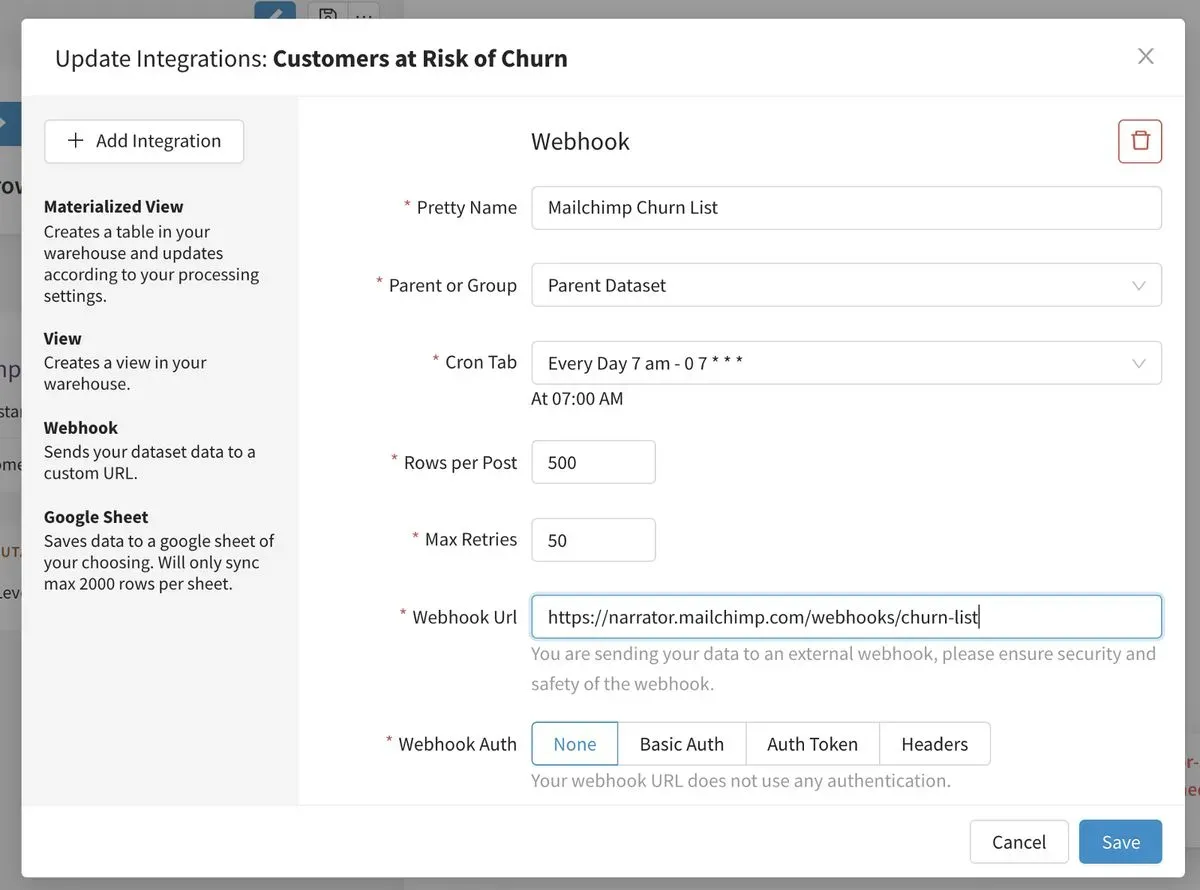
Narrator can export any transformed data from the warehouse as a webhook, so the transformation and integration steps can be done together. You don’t even have to write the table back to the warehouse as a materialized view.
Each dataset in Narrator has its own set of configurable integrations. Here’s a webhook to Mailchimp.
Further Advantages
I skipped some other real problems with point-to-point integrations for the sake of clarity.
But in case you’re not convinced here are additional advantages of the warehouse model
Data consistency: the data warehouse has complete, up to date, and cleaned data (otherwise it’s not a very useful warehouse). If you send the same thing to Salesforce and Zendesk you know that your sales team will have the same view as your customer support team. Any issues found can be fixed in a single spot rather than in multiple integrations.
Unidirectional sync: sending data from the warehouse means that it has to be unidirectional almost by definition. In other words, if I sync something with Salesforce there’s really no way to edit it and send it back.
This drastically simplifies syncing. Everything should have a single source of truth. This includes the business logic around when it can and can’t be modified, and in what ways. Allowing other apps to edit a value either complicates syncing (the owning system might refuse an update, requiring error-handling) or requires duplicating business logic. In the worst case the values in different systems will diverge without anyone knowing.
Maintenance: as with anything, the fewer moving pieces the better. Once you’re stuck with the point-to-point model you’re going to a.) have more integration points and b.) a much wider variety of sync mechanisms. Some might be through native integrations, some by third-party integrations, some through webhooks, some through custom-built APIs (by you of course).
Extensibility: because the warehouse can transform any data in arbitrary ways you can basically sync with everything. There’s a clear path for how to support the next thing your business might want. Sure, it’ll be a bit of work to come up with (say) a list of customers who called support and then used a coupon, but you know how to go about it. From there sending it to Mailchimp is easy.
Data Advocacy: I’m not sure what to call this one — but the more people looking at the same data, the more they’re all on the same page. What I mean by that is if every system is using the same view of an ‘at risk’ customer, then the company will all be speaking the same language. Any issues with it will be caught sooner. Has anyone else worked at a company where the CEO had their own private dashboard and would ask about it? No fun.
