What's missing from the Amplitude and Snowflake partnership
Amplitude and Snowflake's partnership is a great first pass at warehouse-powered data analytics. However, this sync is missing many data team requirements for a complex and secure production data system.



Amplitude just announced its partnership with Snowflake allowing their customers to not only sync their data out of Amplitude into Snowflake, but more importantly sync their data from Snowflake into Amplitude.
Amplitude has always been great for fast and simple data exploration, but until now has been limited by their SDK: engineering teams needed to put trackers all throughout their respective apps and websites just to get data into Amplitude. Data teams are all too familiar with numbers not matching between Amplitude and their BI tool of choice. It’s impossible for a tracking pixel to fire even 90% of the time and match the source of truth in a read-replica database for example.
This shift to allow data to come from Snowflake is a super important step in the right direction allowing Amplitude to take advantage of all the data in your warehouse, not just what’s synced through the SDK. However, in this post I want to illustrate some of the hidden problems that users will face given how the sync is implemented.
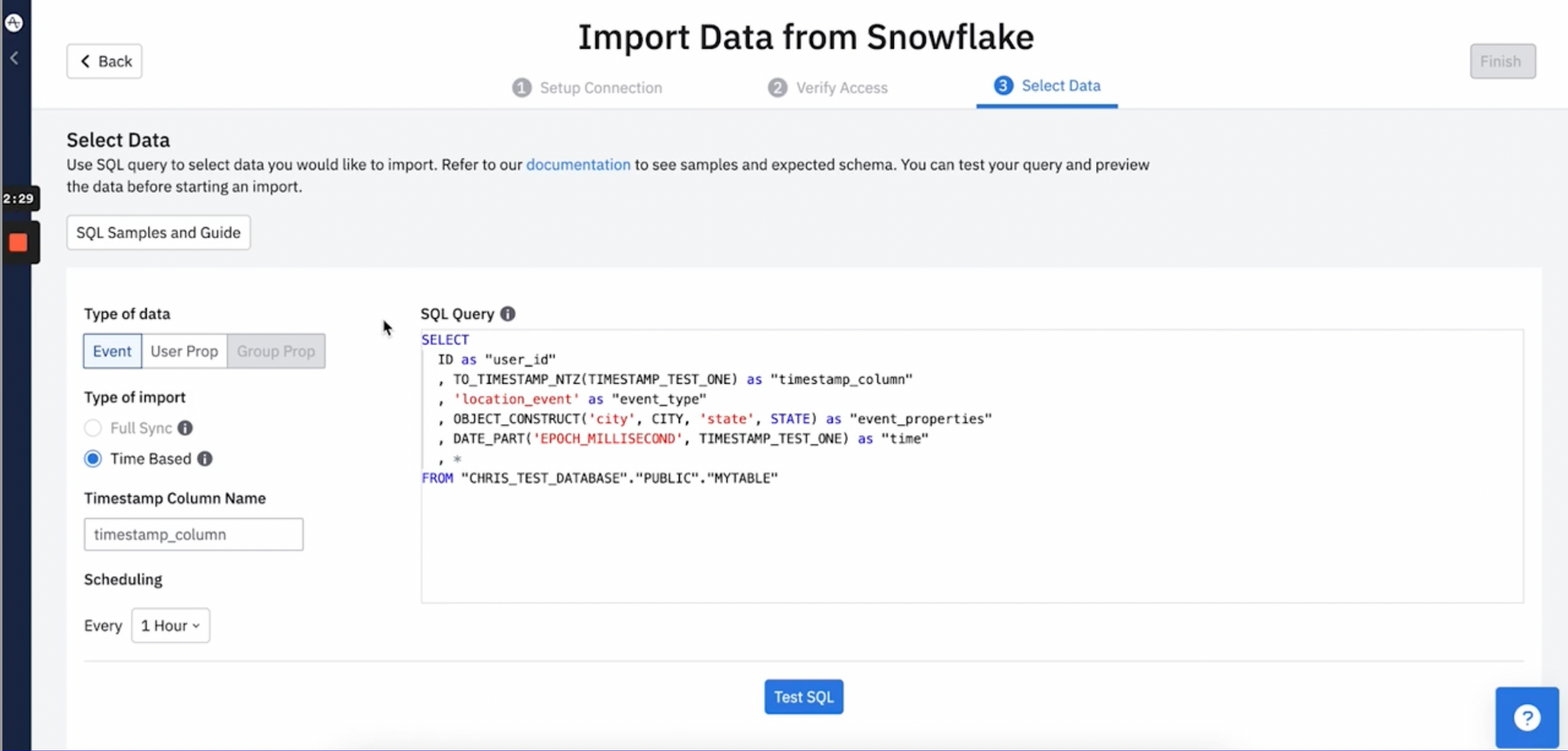
How does the Snowflake to Amplitude sync work?
Instead of having to send data into Amplitude using their SDK, you can do the following:
- Write a simple SQL snippet mapping data from Snowflake into Amplitude events and properties
- Once saved, Amplitude will poll the data every hour and insert it into Amplitude’s database
- Voila! Data is now available in Amplitude
The problems with this approach
Before I continue, I want to be completely transparent: as a founder of Narrator (a data analytics platform that can do quick ad-hoc data analysis in a similar way to Amplitude), I’m clearly biased. However, as we developed our platform and model, we focused specifically on data quality and transparency, which is why we power the platform on top of existing data sources in our users’ data warehouses.
Below are the problems with the Snowflake/Amplitude sync that would be deal breakers for our customers.
Problem 1: Customer data leaving your system poses a security risk
The Snowflake to Amplitude sync sends data out of your data warehouse–a system your data team manages and controls in your own infrastructure–to Amplitude, a system you do not control. GDPR and privacy concerns continue to become a bigger deal and sending custom data out of your systems adds another layer of risk.
Our solution: The event stream data model that Narrator builds and maintains lives in your data warehouse. All processing and querying happens on your data warehouse without data ever leaving your system.
Problem 2: Incremental updates will cause data to diverge
This issue is caused by ETL jobs completing at different times. If you have 2 tables, and one table is up-to-date and another is not, and in your SQL snippet you’re joining those two tables together, when the sync from Snowflake to Amplitude runs, rows will be dropped. When the second table is up to date, it’s now too late.
In other words, the more complex the SQL is, the more likely rows will be dropped. This is why most data modeling/transformation tools (dbt for example) default to materialized views. With a materialized view, it deletes and re-creates the entire table each time, which guarantees up-to-date data, but it’s more costly on the warehouse.
Our Solution: Narrator’s infrastructure automatically diffs the data every night and adds any missing rows. This is so Narrator gets the benefit of incremental updates, because they’re less costly for large datasets without any dropped rows.
Problem 3: Identity resolution across multiple devices and sources
When connecting users across disparate sources, depending on `identify` calls from the Amplitude SDK won’t be enough. Data requires stitching an identity across multiple sources (i.e. clicked an email and got redirected to a new site, viewed the checkout page of an order they just placed on a different device). And any time a user is identified they’d need to update historical mappings to ensure all the relevant activities are attributed to each customer. Based on what we’ve seen so far from Amplitude, you’ll only be able to sync data into Amplitude that’s already been identified.
Our Solution: Narrator allows identity resolution through small SQL snippets containing the logic for each association. If you change your mind, just update the SQL snippet and Narrator will automatically remap history. This level of control is how our customers get to >95% of their users’ identity stitched together. Read more here.
Problem 4: No more single source of truth
By pushing data out of Snowflake and into Amplitude, it’s not clear where the events came from. When you see a “Received Email” activity, did that come from Mailchimp? Salesforce/Marketo? Braze? Etc… It’s very difficult to validate where those events came from because you’ve lost all context. The data team will continue building models on Snowflake, and now you have dashboards powered by the warehouse, and separate Amplitude explorations with data in a completely different place.
Our Solution: Narrator’s data model is built inside the data warehouse. Any ad-hoc question is just generating SQL on the warehouse under the hood. This allows fast exploration and answering ad-hoc questions but also provides transparency and control. You could go from exploring the data to having the output powering a BI dashboard in a couple of clicks.
Problem 5: Warehouse lock in
Snowflake is great, but there are plenty of amazing data warehouses out there both existing (Redshift, BigQuery, etc…) and new (Starburst, etc…). As of right now, the Amplitude sync only applies to Snowflake users.
Our Solution: Use whatever warehouse you want!
Conclusion
The Amplitude x Snowflake partnership is a great start as we’re happy to see the world embrace warehouse-powered data analytics. This Snowflake sync will certainly improve over time, but in this first version, Amplitude does not cover many data team requirements for a complex and secure production data system.
For now, Narrator offers a warehouse powered data analytics platform built for the reality of how data needs to be managed on an enterprise scale to maintain data integrity, trust, and security. If you’re interested in seeing what Narrator can do for your team, check out a demo today.
