Using PostgreSQL as a Data Warehouse
With some tweaking Postgres can be a great data warehouse. Here's how to configure it.


Photo by Ryan Parker / Unsplash
At Narrator we support many data warehouses, including Postgres. Though it was designed for production systems, with a little tweaking Postgres can work extremely well as a data warehouse.
For those that want to cut to the chase, here's the tl;dr
- don't use the same server as your production system
- upgrade to pg 12+ (or avoid common table expressions in your queries)
- go easy on indexes – less is more
- consider partitioning long tables
- ensure you're not I/O-bound
- vacuum analyze after bulk insertion
- explore parallel queries
- increase statistics sampling
- use fewer columns on frequently-queried tables
- add a datediff function
- at scale consider a dedicated warehouse
Differences Between Data Warehouses and Relational Databases
Production Queries
Typical production database queries select a few number of rows from a potentially large dataset. They're designed to answer lots of these types of questions quickly.
Imagine a web application – thousands of users at once might be querying for
select * from users where id = 1234
The database will be tuned to handle tons of these requests quickly (within milliseconds).
To support this, most databases, Postgres included, store data by rows – this allows efficient loading entire rows from disk. They make frequent use of indexes to quickly find a relatively small number of rows.
Analytical Queries
Analytical queries are typically the opposite:
- A query will process many rows (often a large percentage of an entire table)
- Queries can take several seconds to several minutes to complete
- A query will select from a small number of columns from a wide (many-column) table
Because of this dedicated data warehouses (like Redshift, BigQuery, and Snowflake) use column-oriented storage and don't have indexes.
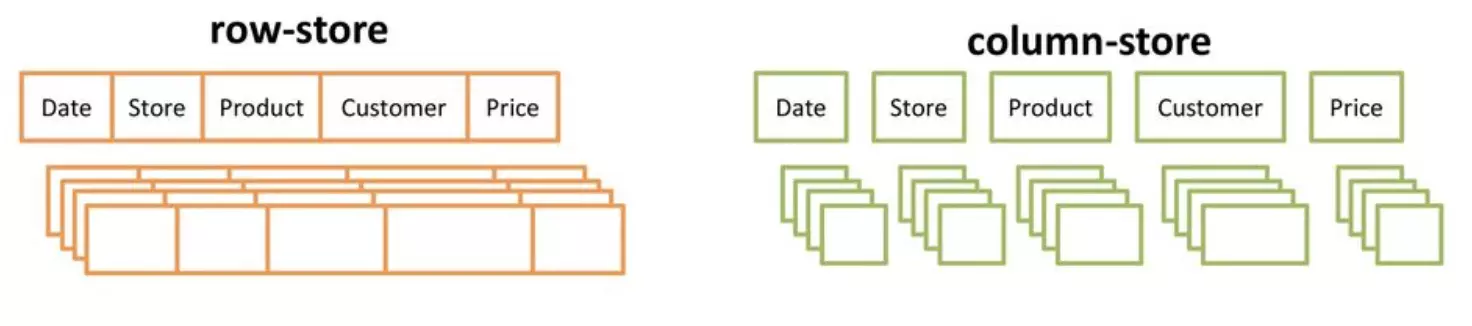
Holistics.io has a nice guide explaining this in a (lot) more detail.
What this means for Postgres
Postgres, though row-oriented, can easily work with analytical queries too. It just requires a few tweaks and some measurement. Though Postgres is a great choice, keep in mind that a cloud-based warehouse like Snowflake will (in the long run) be easier to manage and maintain.
Configuring Postgres as a Data Warehouse
Word of caution: do NOT use your production Postgres instance for data reporting / metrics. A few queries are fine, but the workloads for analytics differ so much from typical production workloads that they will have a pretty strong performance impact on a production system.

Avoid Common Table Expressions
Common table expressions (CTEs) are also known as 'WITH' queries. They're a nice way to avoid deeply nested subqueries.
WITH my_expression AS (
SELECT customer as name FROM my_table
)
SELECT name FROM my_expression
Unfortunately Postgres' query planner (prior to version 12) sees CTEs as a black box. Postgres will effectively compute the CTE by itself, materialize the result, then scan the result when used. In many cases this can slow down queries substantially.
In Narrator, removing 3 CTEs from some of our common queries sped them up by a factor of 4.
The easy fix is to rewrite CTEs as subqueries (or upgrade to 12).
SELECT name FROM (
SELECT customer as name FROM my_table
)
It's a bit less readable with longer CTEs, but for analytics workloads the performance difference is worth it.

Use Indexes Sparingly
Indexes are actually less important for analytics workloads than for traditional production queries. In fact, dedicated warehouses like Redshift and Snowflake don't have them at all.
While an index is useful for quickly returning a small number of records, it doesn't help if a query requires most rows in a table. For example, a common query at Narrator is something like this
Get all email opens per customer and compute the conversion rate to viewing the home page grouped by month.
Without writing out the SQL it's pretty clear this query could cover a lot of rows. It has to consider all customers, all email opens, and all page views (where page = '/').
Even if we had an index in place for this query, Postgres wouldn't use it – it's faster to do a table scan when loading many rows (simpler layout on disk).
Reasons not to use indexes
- For many analytics queries it's faster for Postgres to do a table scan than an index scan
- Indexes increase the size of the table. The smaller the table, the more will fit in memory.
- Indexes add additional cost on every insert / update
When to use an index anyway
Some queries will be much faster with an index and are worth the space. For us, we frequently query for the first time a customer did something. We have a column for that (activity_occurrence) so we build a partial index.
create index first_occurrence_idx on activity_stream(activity) where activity_occurrence = 1;

Partitioning
Partitioning tables can be a great way to improve table scan performance without paying the storage cost of an index.
Conceptually, it breaks one bigger table into multiple chunks. Ideally most queries would only need to read from one (or a small number of them), which can dramatically speed things up.
The most common scenario is to break things up by time (range partitioning). If you're only querying data from the last month, breaking up a large table into monthly partitions lets all queries ignore all the older rows.
At Narrator we typically look at data across all time, so range isn't useful. However, we do have one very large table that stores customer activity (viewed a page, submitted a support request, etc). We rarely query for more than one or two activities at a time, so list partitioning works really well.
The benefits are two-fold: most of our queries by activity do a full table scan anyway, so now they're scanning a smaller partition, and we no longer need a large index on activity (which was being used mostly for the less frequent activities).
The main caveat to partitions is that they're slightly more work to manage and aren't always a performance boost – making too many partitions or ones of vastly unequal size won't always help.

Minimize Disk and I/O
Because table scans are more common (see Indexes above), disk I/O can become fairly important. In order of performance impact
- Ensure Postgres has enough available memory to cache the most commonly accessed tables - or make tables smaller
- Opt for an SSD over a hard drive (though this depends on cost / data size)
- Look into how much I/O is available – some cloud hosting providers will throttle I/O if the database is reading to disk too much.
One good way to check if a long-running query is hitting the disk is the pg_stat_activity table.
SELECT
pid,
now() - pg_stat_activity.query_start AS duration,
usename,
query,
state,
wait_event_type,
wait_event
FROM pg_stat_activity
WHERE state = 'active' and (now() - pg_stat_activity.query_start) > interval '1 minute';
The wait_event_type and wait_event columns will show IO and DataFileRead if the query is reading from disk. The query above is also really useful for seeing anything else that could be blocking, like locks.

Vacuum After Bulk Inserts
Vacuuming tables is an important way to keep Postgres running smoothly – it saves space, and when run as vacuum analyze it will compute statistics to ensure the query planner estimates everything properly.
Postgres by default runs an auto vacuum process to take care of this. Usually it's best to leave that alone.
That said, vacuum analyze is best run after a bunch of data has been inserted or removed. If you're running a job to insert data on a regular basis, it makes sense to run vacuum analyze right after you've finished inserting everything. This will ensure that new data will have statistics immediately for efficient queries. And once you've run it the auto vacuum process will know not to vacuum that table again.

Look at Parallel Queries
Postgres, when it can, will run parts of queries in parallel. This is ideal for warehousing applications. Parallel queries add a bit of latency (the workers have to be spawned, then their results brought back together), but it's generally immaterial for analytics workloads, where queries take multiple seconds.
In practice parallel queries speed up table or index scans quite a bit, which is where our queries tend to spend a lot of time.
The best way to see if this is running as expected is to use explain. You should see a Gather followed by some parallel work (a join, a sort, an index scan, a seq scan, etc)
-> Gather Merge (cost=2512346.78..2518277.16 rows=40206 width=60)
Workers Planned: 2
Workers Launched: 2
...
-> Parallel Seq Scan on activity_stream s_1
The workers are the number of processes executing the work in parallel. The number of workers is controlled by two settings: max_parallel_workers and max_parallel_workers_per_gather
show max_parallel_workers; -- total number of workers allowed
show max_parallel_workers_per_gather; -- num workers at a time on the queryIf you use explain(analyze, verbose) you can see how much time each worker spent and how many rows it processed. If the numbers are roughly equivalent then doing the work in parallel likely helped.
Worker 0: actual time=13093.096..13093.096 rows=8405229 loops=1
Worker 1: actual time=13093.096..13093.096 rows=8315234 loops=1It's worth trying out different queries and adjusting the number of max_parallel_workers_per_gather to see the impact. As a rule of thumb, Postgres can benefit from more workers when used as a warehouse then as a production system.

Increase Statistics Sampling
Postgres collects statistics on a table to inform the query planner. It does this by sampling the table and storing (among other things) the most common values. The more samples it takes, the more accurate the query planner will be. For analytical workloads, where there are fewer, longer-running queries, it helps to increase how much Postgres collects.
This can be done on a per-column basis
ALTER TABLE table_name ALTER COLUMN column_name set statistics 500;Or for an entire database
ALTER DATABASE mydb SET default_statistics_target = 500;The default value is 100; any value above 100 to 1000 is good. Note that this is one of those settings that should be measured. Use EXPLAIN ANALYZE on some common queries to see how much the query planner is misestimating.

Use Fewer Columns
This one is just something to be aware of. Postgres uses row-based storage, which means that rows are laid out sequentially on disk. It literally stores the entire first row (with all its columns), then the entire second row, etc.
This means that when you select relatively few columns from a table with a lot of columns, Postgres will be loading a lot data that it's not going to use. All table data is read in fixed-sized (usually 4KB) blocks, so it can't just selectively read a few columns of a row from disk.
By contrast, most dedicated data warehouses are columnar stores, which are able to read just the required columns.
Note: don't replace a single wide table with multiple tables that require joins on every query. It'll likely be slower (though always measure).
This one is more of a rule of thumb – all things being equal prefer fewer columns. The performance increase in practice won't usually be significant.

Add a datediff function
Data warehouses like Redshift, Snowflake, and BigQuery all support datediff – an easy way to count the difference between two timestamps by year, day, hour, etc.
Postgres doesn't have it, so if you do a lot of analytical queries it might be useful to have. It's too long to get in here, but I have another post describing Postgres' missing date diff function along with its implementation.

Consider a data warehouse at scale
The last primary difference between Postgres and cloud-based data warehouses is extreme scale. Unlike Postgres, they're architected from the ground up as distributed systems. This allows them to add more processing power relatively linearly as data sizes grow.
I don't have a good rule of thumb for when a database has gotten too big and should be moved to a distributed system. But when you get there you'll probably have the expertise to handle the migration and understand the tradeoffs.
In my informal testing, with a table between 50-100M rows, Postgres performed perfectly well – generally in line with something like Redshift. But the performance depends on so many factors – disk vs ssd, CPU, structure of data, type of queries, etc, that it's really impossible to generalize without doing some head to head testing.
Citus is worth considering if you're scaling Postgres into billions of rows.
