Why star schema is set up for failure

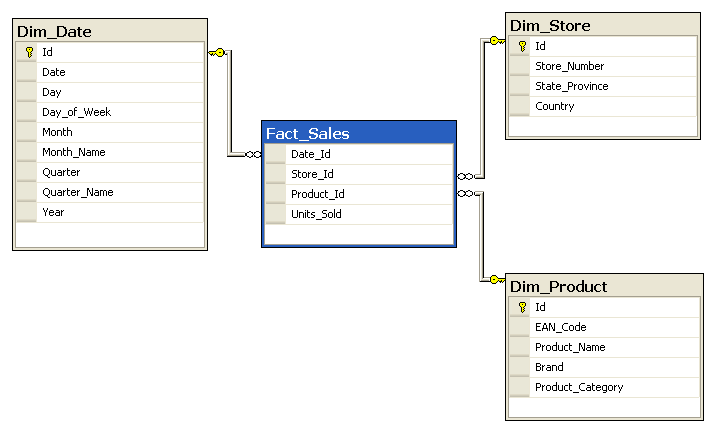
What is star schema?
Star schema is the most common approach to data modeling — primarily made up of fact and dimension tables.
Why you need data modeling
- Your company has a lot of data across many different data sources: website and marketing interactions, internal databases, Salesforce, Zendesk, etc…
- Querying production data directly is dangerous because these systems weren’t designed for analytics
- Therefore, you build an analytics layer that contains all the data you need for analysis, reporting, and BI
How star schema works
You break your analytics data up into:
- Facts or measures (what you want to measure, i.e. leads, sales…)
- Dimensions (how you want to slice your data, i.e. gender, company, contract size…)
Data Engineers create many of these fact and dimension tables on top of your raw production data in your data warehouse, which enables analysis, reporting, and BI.
Where did star schema come from?
Star schema was created because storage was expensive and fact and dimension tables make it easy to aggregate large amounts of data into smaller chunks. With the advances in data warehousing, storage is now super cheap, BUT we’re still using fact and dimension tables.
What’s wrong with star schema if it’s been around for so long?
Companies are different now. Data sources and formats change frequently and companies use data in very different ways.
- In the past, you had one internal database. Now, on day one of starting your new company, you already have tens, sometimes hundreds of tables across all the different SaaS tools and internal databases.
- In the past, you’d define your sales dashboard and not need to change it for months. Now, with everyone on your team being data-driven, you’re asking many more questions on a daily basis.
Your data, and your ability to answer questions rapidly and accurately is your competitive advantage. Therefore, for a competitive company, the number of data questions grows exponentially.
Unfortunately, a star schema is bad at handling change.
When deploying a star schema, data engineers have to imagine all the questions you want to ask (facts/measures) and all the ways you want to ask those questions (dimensions) and it’s truly impossible to capture all of it.
There has to be a correct way to implement star schema, right?
The problem is when you look behind the curtain of each fact and dimension table you’re met with a cryptic 1000 line query. This query is full of crucial assumptions that were necessary when the table was generated months, if not years ago.
And when your CEO asks for a new dimension on the dashboard, no one wants to decode that 1000 line query. It’s too risky. So you end up duplicating the logic to create a similar reporting table with the new dimension and then leave the old table with all the old assumptions intact (no risk). But, now that you have a similar table, you’ve separated the source of truth. There are two tables with similar data, but because of slightly different assumptions dashboards won’t match.

There is a right way to use a star schema, but you have to spend weeks planning out every change before deploying to production. And this is for EVERY table and EVERY change! Then data teams can’t move fast enough to keep up with all the new data questions being asked on a daily basis.
So is it just out of date?
That’s right. The assumptions that created star schema are no longer relevant.
- Data Science and analysis are now more important than building dashboards and plots
- Storage and compute power have gotten way cheaper
- There’s a lot more data, and it changes much more frequently
I’m a new founder who wants to set up a data system, should I use star schema?
Listen, before you do that, go talk to companies that have had a star schema for more than two years. They will tell you the struggles they’ve experienced, and the dangers of this approach: the teams that are being blocked by not being able to get the data they need.
Will you ever use a star schema ever again?
No! Actually, it’s funny because I’ve thought about what would I do if Narrator doesn’t take off. I’ve seen the alternative. With Narrator, every 1 analyst was supporting 8 companies. When I was at my last company we had 40 people supporting only 1 company and answering much fewer questions using a star schema.
That’s why I want everyone to try Narrator. Once you experience it, there’s no going back!
