Handling slowly changing dimensions in an Activity Schema
The simplicity of modeling slowly changing dimensions in an Activity Schema vs a Star Schema


Slowly changing dimensions are a tricky problem in data engineering that every data team will grapple with at one point or another. Traditional approaches require a bit of data engineering jiu-jitsu to model them accurately. But the Activity Schema approach allows for an elegant solution that is easy to implement while maintaining a high degree of accuracy. This blog explains how it's done.
What are slowly changing dimensions?
Slowly changing dimensional data looks just like regular dimensional data ("dim tables"), but the values are slowly changing over time. Slowly changing dimensions (SCDs) are common when representing attributes about a user, like company size. Most companies will stay within the same size bracket year over year, but some companies will grow or downsize. This is a slowly changing dimension because the jump from the 1-20 to 20-100 bracket is an infrequent and barely noticeable change, but it happens slowly over time.
This example may seem obvious, but in practice there are many non-obvious dimensions that behave as SCDs, like contracts, policies, location, etc. Anil Vaitla shares a number of helpful examples in his blog post for software engineers to help you spot slowly changing dimensional data in the wild.
When it becomes a problem
Slowly changing dimensions are a sneaky problem because it may not seem like an important issue to solve for today. Who will notice if a customer changes their address every 2 years? or ...if a user updates their content preferences in the app? But as time goes on, this seemingly harmless edge case can cause big problems for data teams if not handled correctly at the onset.

If not handled correctly, the data in your models will start to diverge from the source of truth. And, even when SCD's are addressed, there is the added challenge of ensuring that historical values are maintained for the data analysts and data scientists to use if needed. Unfortunately most of the standard approaches (types 1 - 7) for handling SCDs are still complicated for a data user to use correctly and tedious for a data engineer to instrument.
This quote from Tom Johnston's article sums it up well...
In brief, there are two things wrong with SCDs. The first is that they inadequately live up to their stated purpose. They are intended to provide history for dimensions; but the history they provide is incomplete. This objection applies to all SCD types, used alone or in combination.
The second is that the costs of using “advanced SCDs” (SCD types 3 – 7) outweigh any cost savings that those advanced SCDs achieve over type 2 SCDs.
No matter how you approach this pesky data, you're likely to run into challenges of some nature.
The Star Schema Approach
There are numerous methods of modeling SCD's with a traditional star schema. I won't go into all of them here, but I will talk about two popular approaches and their downfalls.
Common Approach #1: Maintaining a snapshot history table
This approach maintains a historical record of changing dimensions by taking a "snapshot" of data and appending it to a history table. The data is snapshotted on a regular basis (usually daily) so that we always have a picture of what the world looked like at a given time.
The nice thing about these tables is that they're easy to use. Your data analyst or data scientist will likely use this table often, but ultimately you'll run into some limitations:
- There's a heavy dependency on processing. If a processing error occurs one day (or you undergo scheduled maintenance) you'll miss a snapshot, creating a gap in your history table.
- There will be a continuous need for a finer level of granularity. If you start with a weekly snapshot, your data users will eventually have requirements for daily granularity, or hourly, etc. Ultimately, the underlying need is to understand exactly what changed when, and a snapshot table is not the best way to capture this level of detail. You'll need exact timestamps.
- Your table will become massive. With each update, the data is copied and appended to your history table and, especially with a finer level of granularity (like an hourly snapshot), your table can get really big, really fast. At some point this will slow down your queries and eat up your storage.
Common Approach #2: Maintaining valid_from and valid_to timestamps
With this approach, you'll add a new record any time the data changes and maintain a valid_from and valid_to timestamp for that value. This will accurately capture the changes over time and give the data user enough detail to understand exactly when the data changed.
Unfortunately, these tables are hard to use. Most likely these tables would not be widely adopted - or worse, they would be adopted but used incorrectly - because they require complex conditional joins on the timestamp column. 😰
Data scientists and data analysts do not have the SQL skills of a data engineer, and that's to be expected. Their core skills are data storytelling, visualization, analysis, and statistics; SQL is just a means to an end.
Ultimately, if a table requires conditional joins to use it accurately, we're setting ourselves (and our team) up for failure.
The Activity Schema Approach
The activity schema approach to SCDs overcomes the core challenges we ran into with a star schema.
Benefits
- Easy to instrument and maintain
- Succinct data capture that doesn't create storage bloat in your warehouse
- Provides data users with precise data to know exactly when dimensions change
- Easy for data users to query and combine with their datasets (no conditional joins)
How it works
Whenever a dimension changes, that update is modeled as its own activity in the activity schema to represent when the change occurred and the new value.
Let's consider an example: Account Size
Over time, a customer may change the size of their account. This won't happen often, but when it does the change it will be important to track. In an activity schema, an activity is added to the activity stream each time the account size is updated.
In the journey below, you'll see an Updated Account Size activity each time the account size is updated. There are three activities in this customer's journey because the account size has been changed three times: from 4,800 to 1,300 to 2,500.
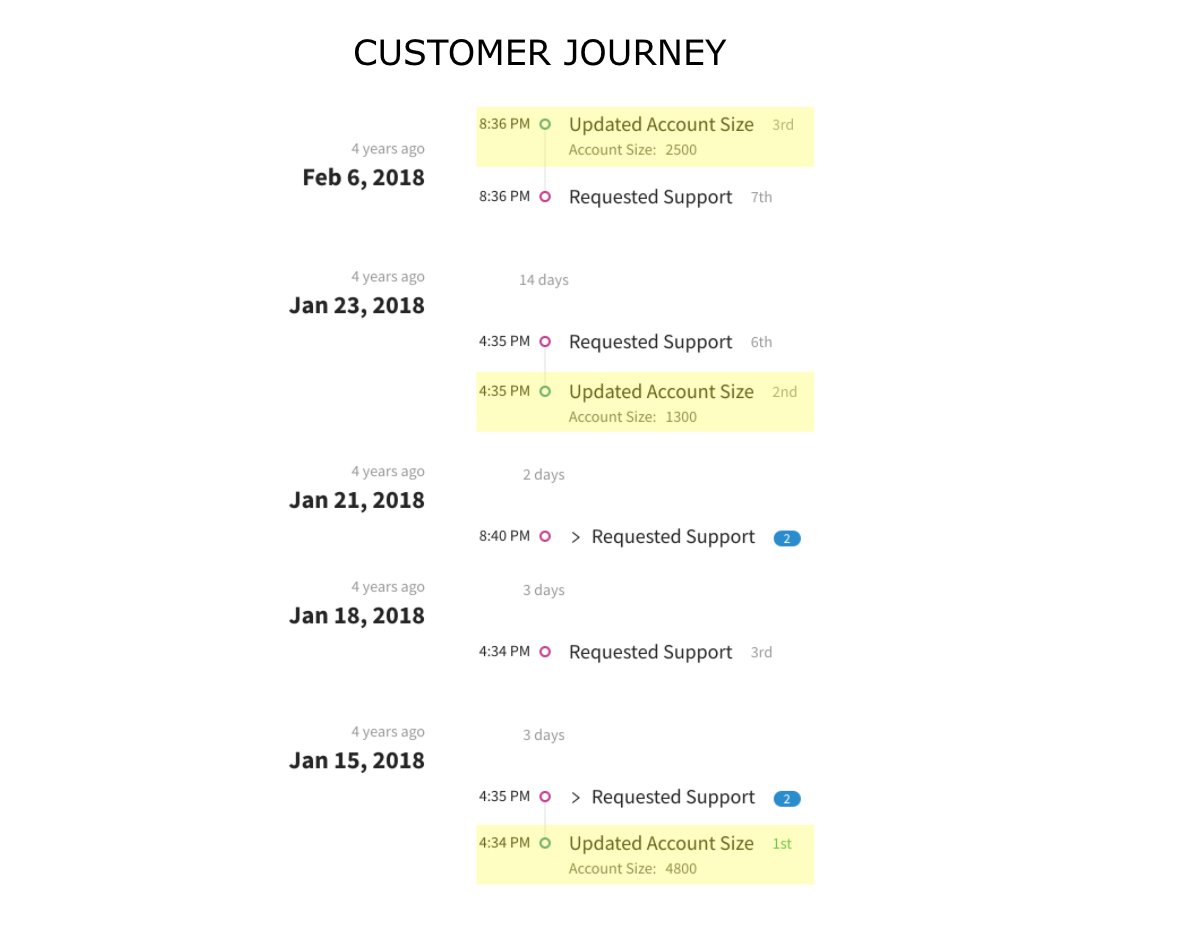
Activities are flexible enough to capture repeated changes over time, so they are perfect for slowly changing dimensions - or frankly, any changing dimensions.
In an activity schema, we're forced to define independent concepts (activities) that are immutable, which solves the problem of SCDs completely. Compare that with the star schema approach, where most SCDs are combined with other tables to make them easier to work with – denormalized to make them easier to query – but then it becomes less flexible and much harder to maintain.
Incremental Updates Are Our Friend
Traditional approaches to SCD's can create a lot of unnecessary bloat in the warehouse or require a lot of processing power to scan the entire table for changes on each processing run. The Activity Schema approach takes advantage of the incremental data processing when adding new activities.
Let's look at the logic for Updated Account Size...
SELECT
-- unique ID for each update
(s.id || s.updated_at) as activity_id
-- each new timestamp creates a new activity record
, s.updated_at as ts
, s.email as customer
, "updated_account_size" as activity
, s.account_size as feature_1 -- new account size
, NULL as feature_2
, NULL as feature_3
, NULL as revenue_impact
, NULL as link
FROM internal_db.account_details s
Note that the timestamp of the Updated Account Size activity is the updated_at timestamp from the account_details table. And, recall that in an activity schema, new activities are added to the activity stream incrementally by default. That means, on each processing run, it checks to see if there are any updated_at timestamps that happen after the last updated_at from the previous run and append any new data to the activity stream. In the case of SCDs, this means that each time a dimension is updated a new updated_at timestamp is assigned and the new value is added to the activity stream to create the history of changes that we were looking at in the customer journey above.
- No excess data storage ✅
The processing only adds new records if the data has changed. - No excess processing ✅
The processing doesn't scan or diff the entire table to identify updates, it simply finds all newupdated_attimestamps after the last run
With the incremental processing of the activity stream, slowly changing dimensions are updated seamlessly without any overhead from the data engineering team.

Easy Usage for the Data User
We've discussed the processing benefits of modeling SCDs with an activity schema, but that's only meaningful if the data end-user can easily use the modeled data. Let's see what that looks like with an activity schema...
The activity schema uses relational operators ("relationships") to assemble activities together into a dataset for modeling or analysis. These operators are the secret to providing flexibility to the data user, without a single conditional join. If you're unfamiliar with the way that datasets are assembled with an activity schema, you can read more about it in this spec.
The activity schema gives data users the flexibility to incorporate SCDs into any dataset without the complexity of conditional joins.
Let's walk through an example of how a data user might incorporate Account Size into their dataset for three different scenarios.
We'll start with a dataset of support requests, based on the Requested Support activity, so each record of our dataset is a single a request that has been submitted by a customer. In an activity schema, it's defined this way:

Consider three ways a data user may want to use the Account Size dimension in the support dataset:
- Using the initial size of the account
- Using the current size of the account
- Using the size at the time of the request submission
All three scenarios are simple to create using an activity schema.
Scenario 1: All support requests with the initial size of each account...

This dataset uses the FIRST EVER relationship to build a dataset with the initial size of the account.
Scenario 2: All support requests with the current size of each account...

This dataset uses the LAST EVER relationship to build a dataset with the current size of the account.
Scenario 3: All support requests with the account size at the time of the request submission...

This dataset uses the LAST BEFORE relationship to find the last time the account size was updated before each support request was submitted. Since this was the last update before the submission, it represents the account size at the time of the request.
Each of these scenarios are simple with an activity schema, requiring no complex logic but providing the flexibility to bring in the SCD as it's appropriate for each new data question.
Activity Schema is the Future
Slowly changing dimensions can be a lot of work, but they don't have to be if you're using an Activity Schema.
With this approach, processing is minimal, the data engineering is simple, and the end-data user can incorporate them into any dataset with ease. If you're interested trying the Activity Schema approach for yourself, I recommend checking out Narrator, a data platform that leverages the activity schema to enable you to build datasets and answer questions in minutes. Setup is quick (< 1 day) and you can experience the simplicity of modeling SCDs in an activity schema using your own data.
