Synthetic Data: Generating realistic user timestamps in SQL
How to generate timestamps in SQL that match realistic user behavior data.


This is the second in a three part series showing how we generate interesting fake data to demo Narrator. Part 1 described how to create a numbers table.
Generating time series data can extremely useful for testing, debugging, and demoing. For example, whenever we demo Narrator's data platform we show generated data from a fake company. The data is all generated by creating user events at specific (randomish) times. Creating realistic timestamps is at the core of this process.
Unfortunately, creating realistic synthetic timestamps in SQL is pretty unintuitive. Postgres has a neat generate_series() function that can create timestamps, but it'll create them evenly (which is quite useful, but not what we want).
Here we'll show how we create timestamps that follow reasonable usage patterns. We'll start with a simple case and build it up bit by bit.
The code below will all be for Redshift. It should be straightforward to convert to any other warehouse.
The basic process is to pick a target start and end date, the number of timestamps needed, and use a numbers table to select the right number of rows. From there a little math will create timestamps in that interval with the properties we want.
Random Timestamps
The first step is to create timestamps evenly spread throughout our time interval.
The code above is not too bad. It creates timestamps on a per-minute basis. The timestamps are is random so there's no truly obvious pattern.
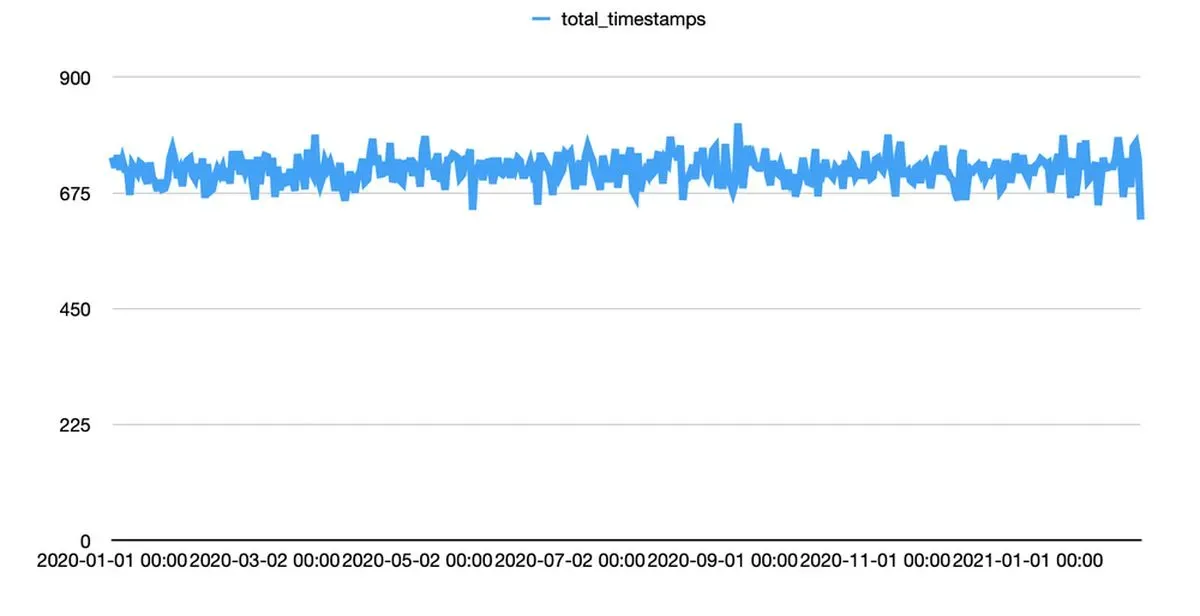
Well, there is one obvious pattern – the slope is perfectly straight. That's not super realistic. Let's try modeling usage increasing over time.
Increasing Timestamps
Let's assume our timestamps represent user activity – say website sessions. Over time this usage is going to increase, so we should have our synthetic timestamps follow that.
An exponential function is a great one to follow, since it measures compounding growth. It's generally of the form

We'll use the form f(x) = rx for simplicity's sake. For example, 2x looks like this:
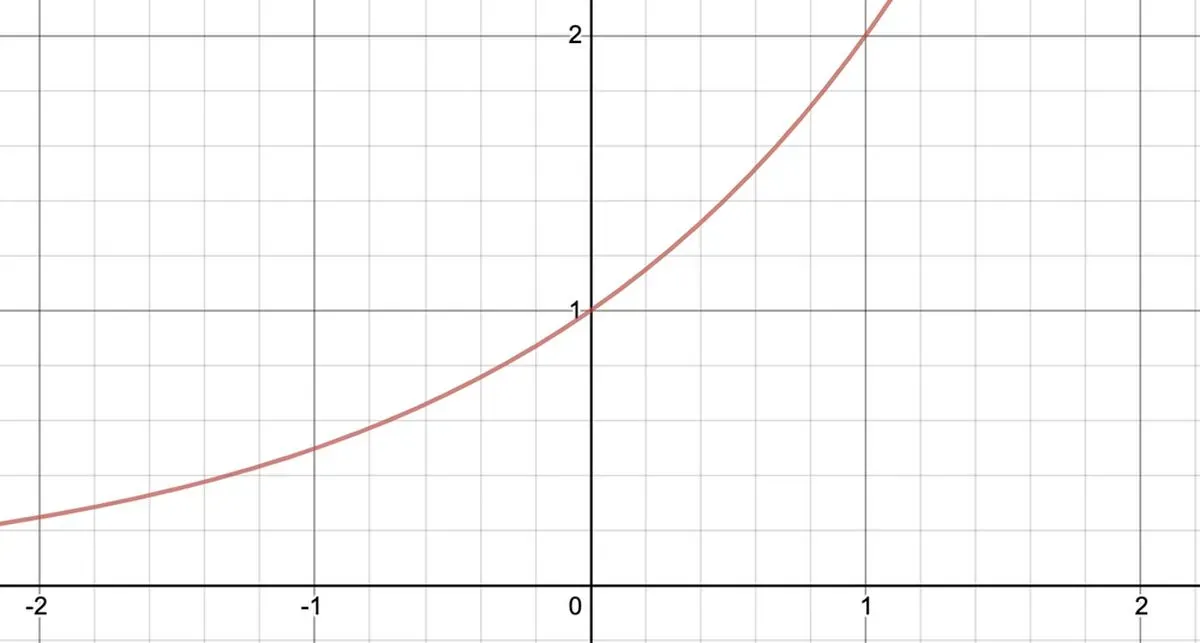
This models the hockey-stick growth all startups want to see and is actually a fairly good representation of actual user growth.
So the problem is how to generate timestamps that follow a function. The code to do this isn't too crazy:
Which looks like this:
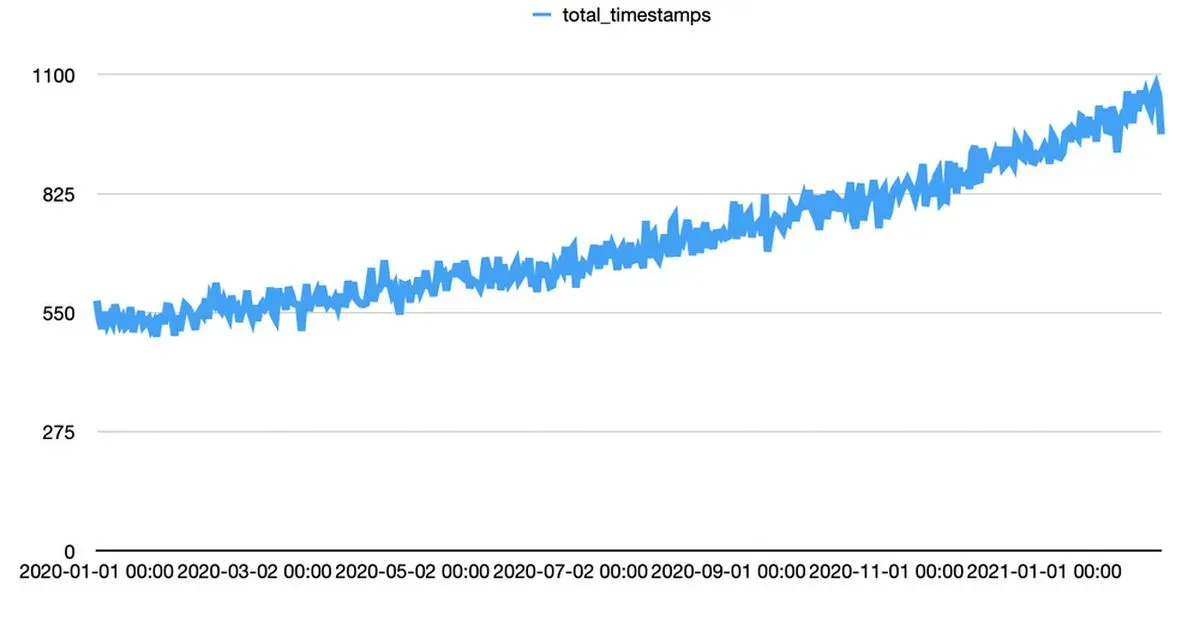
So what's going on?
First we're using the function 2x - 1 to generate a y value between 0 and 1 for x between 0 and 1. This simplifies things a lot. We'll deal with values not between 0 and 2 in the next section
So we have random() as x and 2^x - 1 as y
The main difference from before is that we'll use y instead of x to create the actual timestamp value.
We also offset y from the end of the time period instead of the beginning. This is because for early dates the values of y are more similar to each other (the flatter part of the curve). That means in a given time span (say a day) there are more of them, making the curve trend down. Negating y this way basically mirrors the graph around the y axis and solves that issue.
Adjusting the Output
That looks nice, but what if we want to more carefully control the function we're using? For example, let's make the graph much steeper. To do this we just have to change the function.
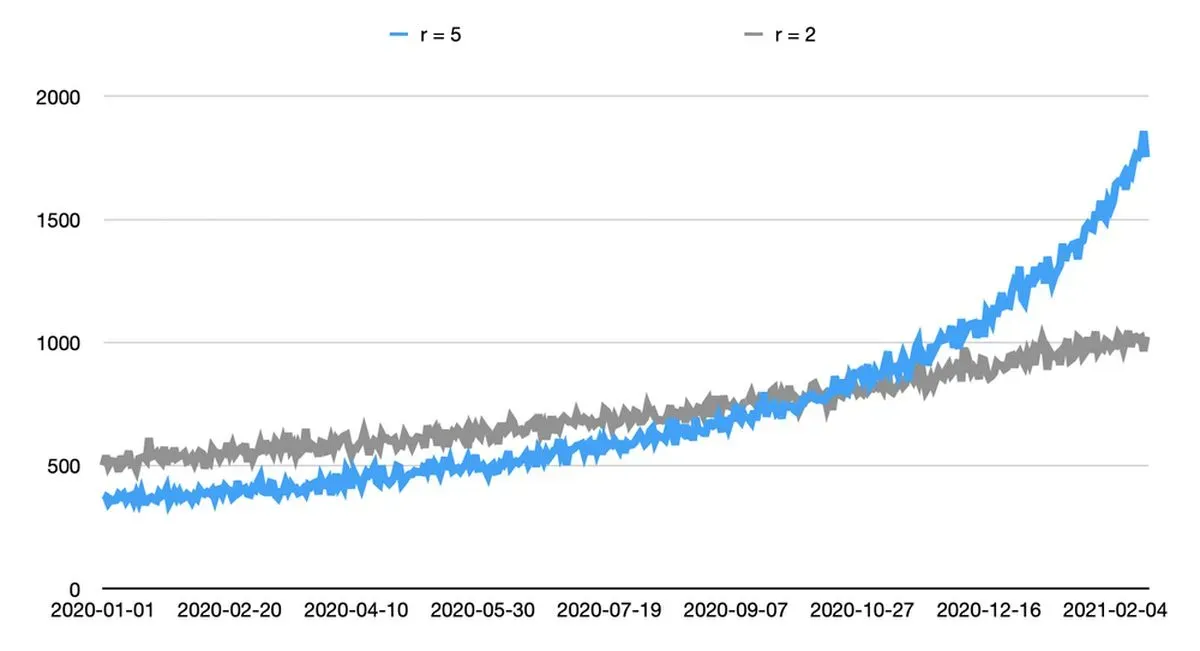
For an exponential function we'll get a steeper curve if we give the growth rate a higher number: going from f(x) = 2x to say f(x) = 5x. Pretty straightforward.
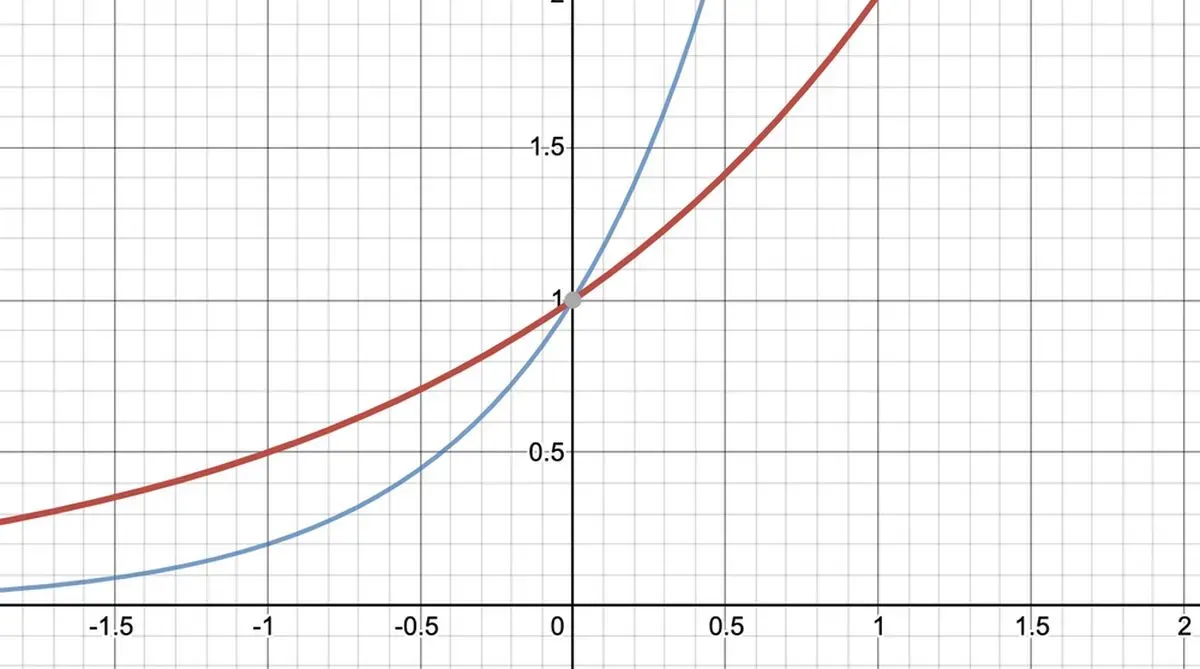
In the last section we crafted our function so that for all values of x from 0..1 y is also between 0..1. That simplification won't be possible this time, so we'll have an additional step where we scale y back down.
Here it is
The code is nearly the same. We just have to do a simple linear interpolation of y to get it between 0 and 1.
It's fairly easy to see the graph is now steeper, and that there are fewer timestamps earlier, and more timestamps later, than before.
Incremental Creation
This is great at creating a whole set of timestamps, but what if you want to create them a bit at a time? We do this with our demo account – every day we add new user events based on these timestamps to make the demo look like it's live and up to date.
In the examples above we generated timestamps between some time in the past and now. This won't work for incremental generation, since subsequent days won't line up. Picking 24 hours ago and now as the two endpoints will give a discontinuity as each new day effectively starts the curve over.
The simplest way to have one overarching curve across multiple runs is to fix both the start and end dates. In other words, pick a future date for the end and stick to it (say 5 years in the future). From there simply filter on timestamp in the select query to generate the date range you need
select
date_trunc('day', ts)::date AS day,
count(1) as total_timestamps
from quickly_increasing_timestamps
where ts > '2021-02-02'::timestamp and ts < 2021-02-03'::timestamp
group by day
order by day ascWrapping Up
There it is. A nice set of auto-generated timestamps that follow any curve we'd like. In a future post we'll dive into how we use these synthetic timestamps to build out an entire set of realistic customer behaviors.
