Data Dictionary: A Symptom, not a Solution
Having a data dictionary is really a symptom of a complex data modeling layer. With a simpler layer it's possible to avoid maintaining a dictionary altogether.


Photo by Dmitry Ratushny on Unsplash
As a product facing software engineer at a data solutions company, I am often confronted by the stark difference between my job and the job of a data engineer. Nothing serves as a better symbol of this difference than a data dictionary. In this article I’ll explain why a data dictionary exists, what’s wrong with it, and how you can structure your data to make dictionaries obsolete.
Complex Data Models are Huge and Constantly Changing
Whether you are a data engineer or a traditional software engineer you will mutate and create new code all the time. A major difference between the two groups is scale. As a product engineer I try to create small functions and components, each only responsible for encapsulating the smallest logic possible. I can then take these small building blocks and put them together to make or update a larger feature. Changes to an existing block are usually not too difficult as I only have to look at a couple of these smaller building blocks to see what is happening in a particular piece of code.
Data engineers on the other hand, rely on multi-thousand line queries, stacked on top of one another creating a complex web of dependencies. Context and logic are built into the model itself, trying to account for assumptions about the data at the time of their authoring. They are opinionated as they are built to answer questions and tell a story. This size and complexity makes it difficult to understand what is happening inside of your models, especially when you have a team of data engineers updating, versioning, and analyzing the same data across your whole company.
When a stakeholder asks for a new insight, a team of data engineers might have to spend weeks trying to solve a request. The stakeholder may come back and ask for tweaks to a slightly different subset of the same question. Because the models are so complex, data engineers will often create a whole new model to encapsulate the additional constraints and you're back at it for weeks!
Wanting Context to Explain the Complexity
Needless to say, with all these interdependent, constantly mutating models it would be helpful to have a map of sorts, right? Enter the data dictionary. Now up to this point, having context and insight into what your data system is doing seems like a natural want, like an owner’s manual to a new car. Unfortunately that analogy breaks down quickly, as the car isn't going to change after you drive it off the lot (other than the price!), while your data system is.

Maintaining a Data Dictionary is a Business in Itself
As often as your models are changing and multiplying, an accurate dictionary must be updated to reflect those changes. This has to be a team wide commitment, which can be difficult because different members are working on different questions at different times. Otherwise it will quickly fall out of date and its accuracy and validity will decline. It only takes one incorrect piece of documentation or missing table for an analyst to lose trust in the dictionary as a whole. You’re left with suspect context at best.
But let's say you and your team actually take the time to keep your dictionaries up to date. Congratulations, that probably took an incredible amount of effort, discipline, and coordination as thoroughly maintaining a dictionary of thousands of mutating models sounds like a Herculean undertaking. In fact, there are whole companies that are dedicated to providing this service.

tldr - RIP Data Dictionary
Ironically, it's this expansive context that will ultimately render it somewhat useless. If you are able to successfully document the data, your dictionary becomes verbose, thorough, and therefore too long for anyone to read and digest. You can have incomplete dictionaries that are somewhat inaccurate and lack the true nuance of your data system, all the way to detailed, expensive dictionaries that no one will bother to read.
What began as a desire to better understand a complex system starts to feel like it's more trouble than it's worth. That's why I say that dictionaries are more of a symptom of complex data models, rather than a solution.
Locally Optimistic has a great post describing why data dictionaries may not be worth it, and suggest the answer is a simpler, single source of truth modeling layer.
So why all the complexity?
So why create complex data models in the first place? One of the reasons for this complexity comes from trying to hide away the complexity from future users. Working more on the product side, this makes total sense to me. I want to be able to look at a function or component's name, see its arguments/props, and be able to reuse it easily. I don't want to re-write it every single time and I don't necessarily want to deep dive into its structure until there are issues with it. Makes sense.
But, as I mentioned in the beginning, there are a couple differences between the data world and the product world. First, my components and functions are never a thousand lines, while a data query may be. Second, my components and functions don't change as frequently as data models. This means that the next time an analyst or engineer comes across a model and needs to unpack it they either have to:
- Take their best, educated guess as to what the query means (increasing their risk of being wrong).
- Rewrite the query themselves, leading to more data models and even more complexity!

Data folks have an impossible job in this environment. They are expected to decipher an ever evolving history and to see far into the future. Each of these predictions make it into the data model and are based on assumptions that will ultimately expire. Every iteration and new prediction leads to further complexity for future engineers.
...There must be a simpler, more robust way of doing this.
Activity Schema for the Win!
At Narrator we model all our warehouse data as an activity schema.
Now when I say simple, I mean really simple. We're talking 20-30 lines per query. Instead of creating complex data models, you can define your raw business concepts ('opened_email', 'purchased_product', ...) as simple queries that just represent the what.
Traditional data modeling describes the business logic within itself (i.e. “which lead source should we assign to each new customer if they interact with an email and the website” instead of a simple SQL model that only consists of a “visited website” activity and a “submitted lead” activity).
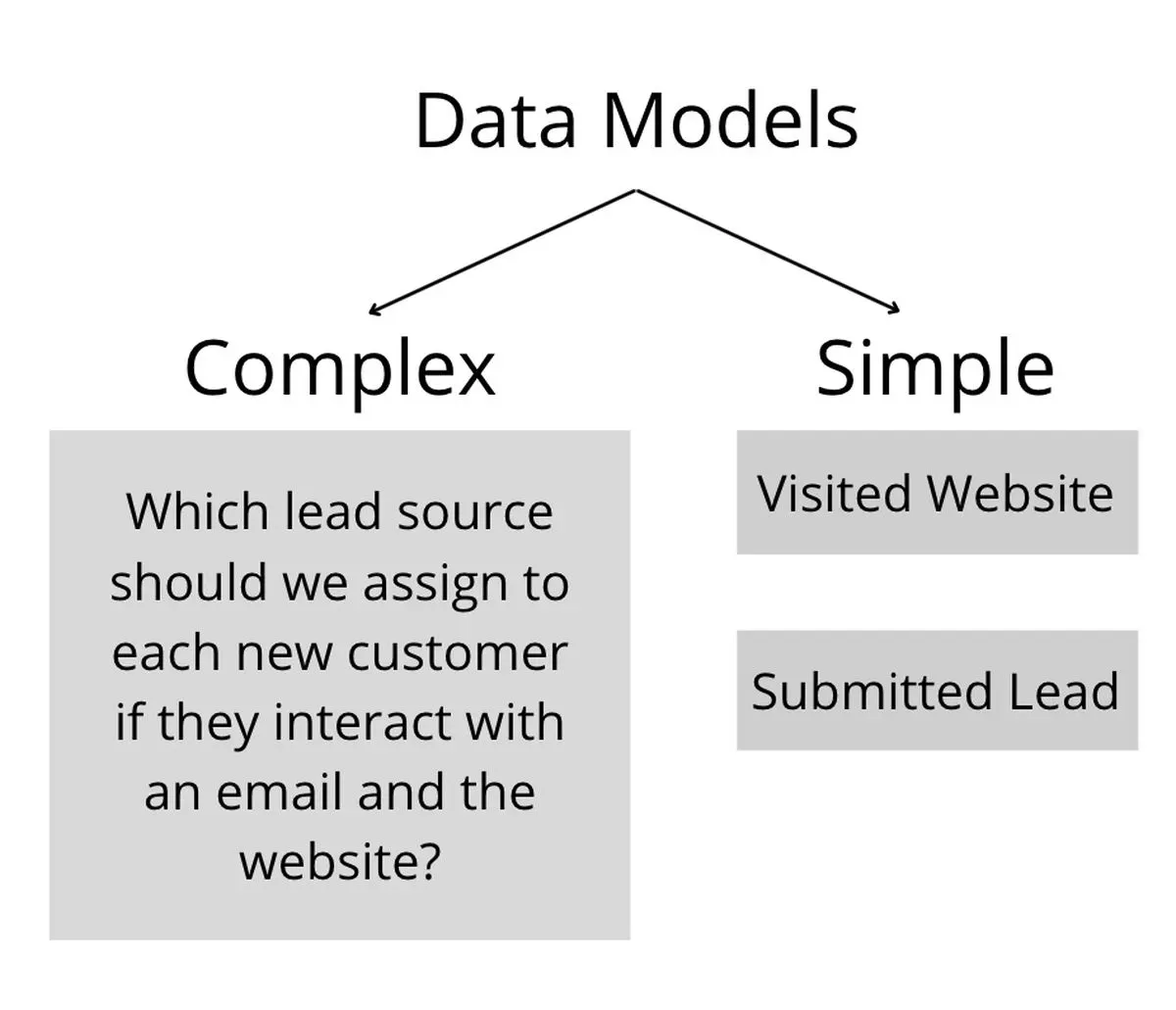
These small activities aren't going to change too much throughout their life. Visiting a website and submitting a lead are pretty static concepts that queries representing them won't have to update for any time soon. Business logic will change, but these core concepts will not.
Moreover, business logic you use may differ across different contexts depending on which questions you’re trying to answer. Instead of trying to code that context into the table itself, it’s better to have defined building blocks and focus on their “assembly” to manage specific logic. By strictly limiting your queries to their business concept, the query stays within one data source. This leaves you with many smaller queries representing single concepts that often only take up the aforementioned 20-30 lines. Below is an example of a simple query for “Completed Order” from Shopify:
By stripping away all the assumptions and complexity, we're left with resilient, reusable building blocks. At this point, all we have to do is assemble these blocks to fit our questions. At Narrator we've found that the average company can define all of their business concepts into 20-40 of these small queries. We stack all of these queries into a single, time-series table and then direct our queries to that single table. See how we make one of these queries here!
Don't Need a Dictionary Anymore
A data dictionary isn't really relevant in an architecture like this. In fact, these small queries kind of serve as a data dictionary in themselves. All you have to do is read 30 lines of SQL and you can understand what that query represents. And because every query just represents what they are, you don't have to worry about cascading dependencies.
These self-contained, simple definitions allow us to ask complex questions in a fraction of the time it takes to write a whole new data model. For example, say you want to know all the completed orders that occurred after a customer received an email. All that takes at Narrator is:
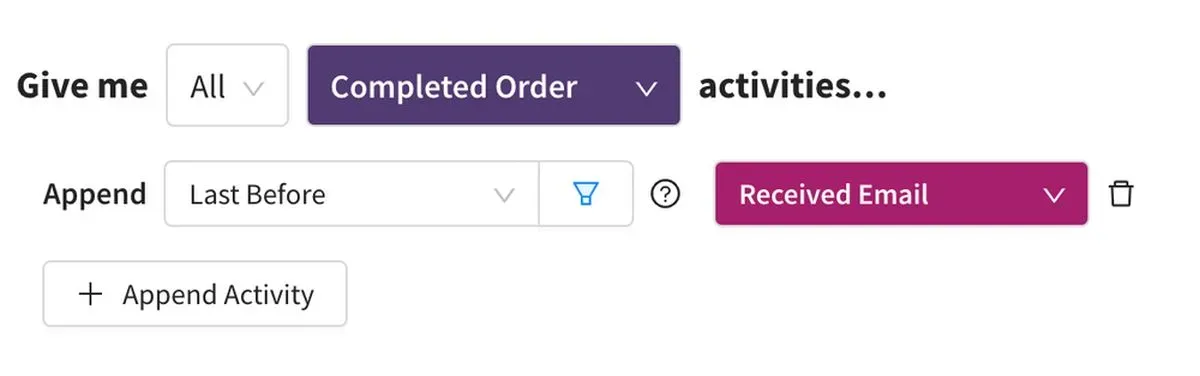
But wait, there's more!
As I mentioned, I don't come from a data background. This question might have taken a full data team weeks to answer. It took me under a minute (including generating the dataset). Say I want to update it to specific types of emails? All I have to do is add a filter and re-run the dataset. A data team doesn't have to create a whole new model to pivot to shifting criteria.
The point is that data definitions are a symptom of complex SQL, while much simpler SQL is a potential solution. You don't need definitions at all if you can break down all your models into bare-bone queries that just explain what they are. The added benefits of reliability, consistency, speed, and adaptability are a nice perk too.
